متا اخیراً به دلیل استفاده از یک نسخه آزمایشی و منتشر نشده از مدل هوش مصنوعی Llama ۴ Maverick به منظور کسب امتیاز بالاتر در یک بنچمارک مورد انتقاد قرار گرفته است. این اقدام منجر به عذرخواهی و تغییر سیاستهای برگزارکنندگان بنچمارک شد، به طوری که امتیاز نسخه اصلاح نشده و اصلی ماوریک به جای نسخه بهینه شده در نظر گرفته شد.
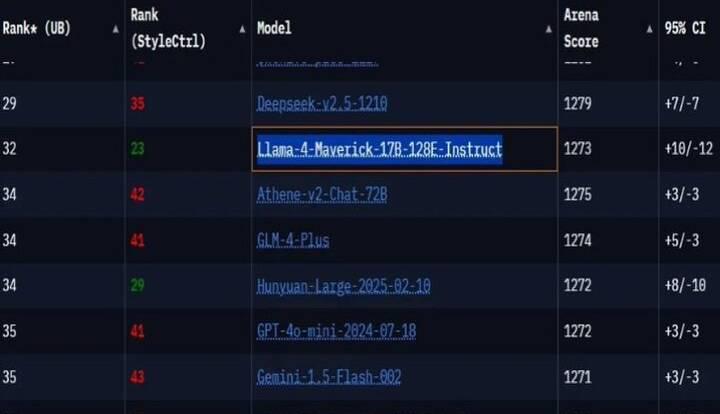
بر اساس گزارش تک کرانچ، نسخه اصلی ماوریک با نام «Llama-۴-Maverick-۱۷B-۱۲۸E-Instruct» در ردهبندی پایینتری نسبت به مدلهای پیشرو مانند GPT-۴-o از OpenAI، Claude 3.5 Sonnet از Anthropic و Gemini 1.5 از گوگل قرار دارد.
متا در واکنش به این انتقادات، با انتشار جدولی توضیح داد که نسخه آزمایشی Llama-۴-Maverick-۱۷B-۱۲۸E-Instruct برای مکالمات بهینه شده بود و عملکرد بهتری در LM Arena، جایی که ارزیابان انسانی مدلها را مقایسه میکنند، از خود نشان داده است. با این حال، استفاده از بنچمارک LM Arena به عنوان معیار قطعی عملکرد هوش مصنوعی مورد تردید است و ساخت مدلی صرفاً برای عملکرد بهتر در یک بنچمارک میتواند گمراهکننده باشد و ارزیابی عملکرد واقعی هوش مصنوعی در کاربردهای مختلف را دشوار سازد.
سخنگوی متا در بیانیهای اعلام کرد که این شرکت نسخههای مختلفی از مدلهای هوش مصنوعی سفارشی را آزمایش میکند و نسخه Llama-۴-Maverick-۰۳-۲۶-Experimental در واقع یک نسخه بهینهشده برای چتبات بوده که در LM Arena عملکرد خوبی داشته است. متا در حال حاضر نسخه منبع باز این مدل را منتشر کرده و منتظر بازخورد توسعهدهندگان در مورد نحوه استفاده و شخصیسازی Llama۴ است.